BRepCLIP
Contrastive Multimodal Pretraining on BRep Primitives for CAD Understanding
DFKI Kaiserslautern · RPTU Kaiserslautern-Landau · MindGarage
Overview
Native CAD structure as the substrate for multimodal understanding.
Point clouds discard analytic surface types, curve primitives, and topology. BRepCLIP keeps faces and edges as first-class CAD entities, tokenizes them with separate face and edge vocabularies, and trains a transformer encoder for open-vocabulary CAD retrieval and evaluation.
Core Contributions
What BRepCLIP brings
Represents CAD models through typed face and edge primitives rather than unordered points.
Uses separate codebooks for surface geometry and curve geometry.
Aligns BRep geometry with text descriptions and multiview image renderings.
Provides a structure-aware similarity metric for text- and image-conditioned CAD generation.
Pipeline
How BRepCLIP works
The pipeline is intentionally split into two stages: primitive tokenization first, followed by contrastive alignment with text and image encoders.
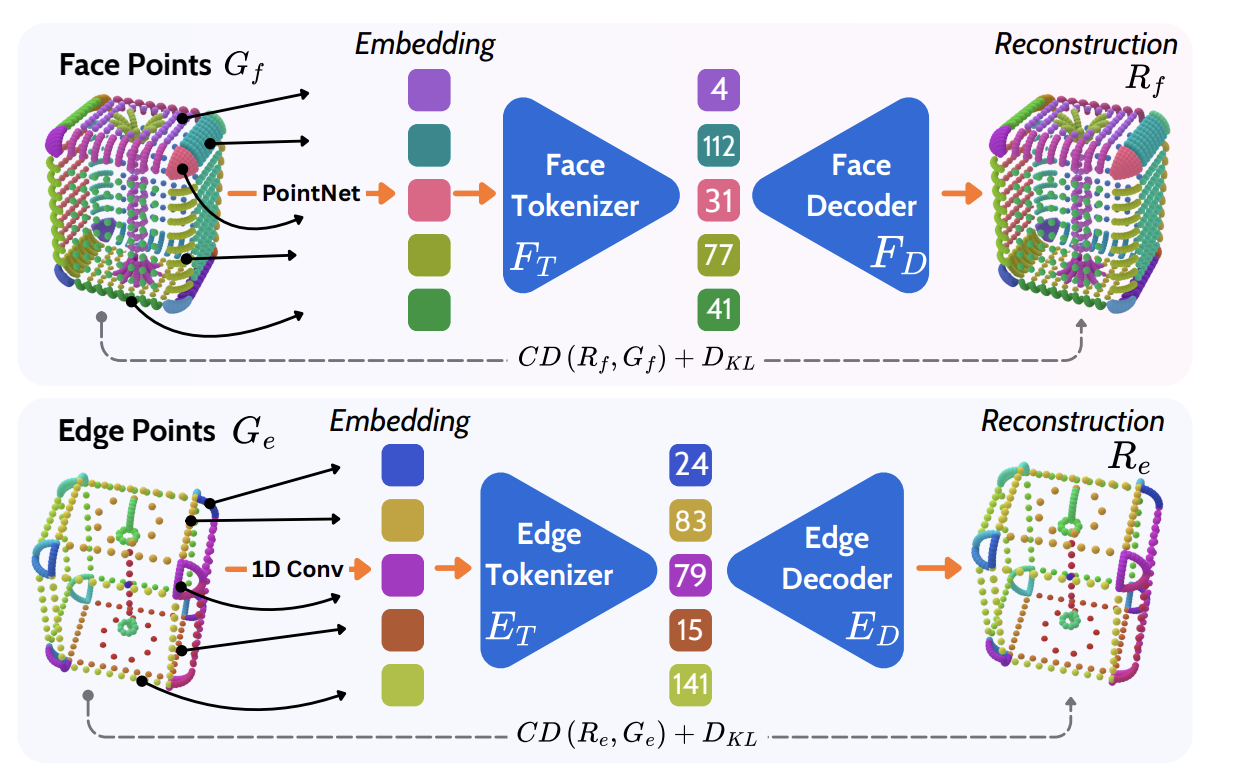
Stage 1
Hybrid face-edge tokenization
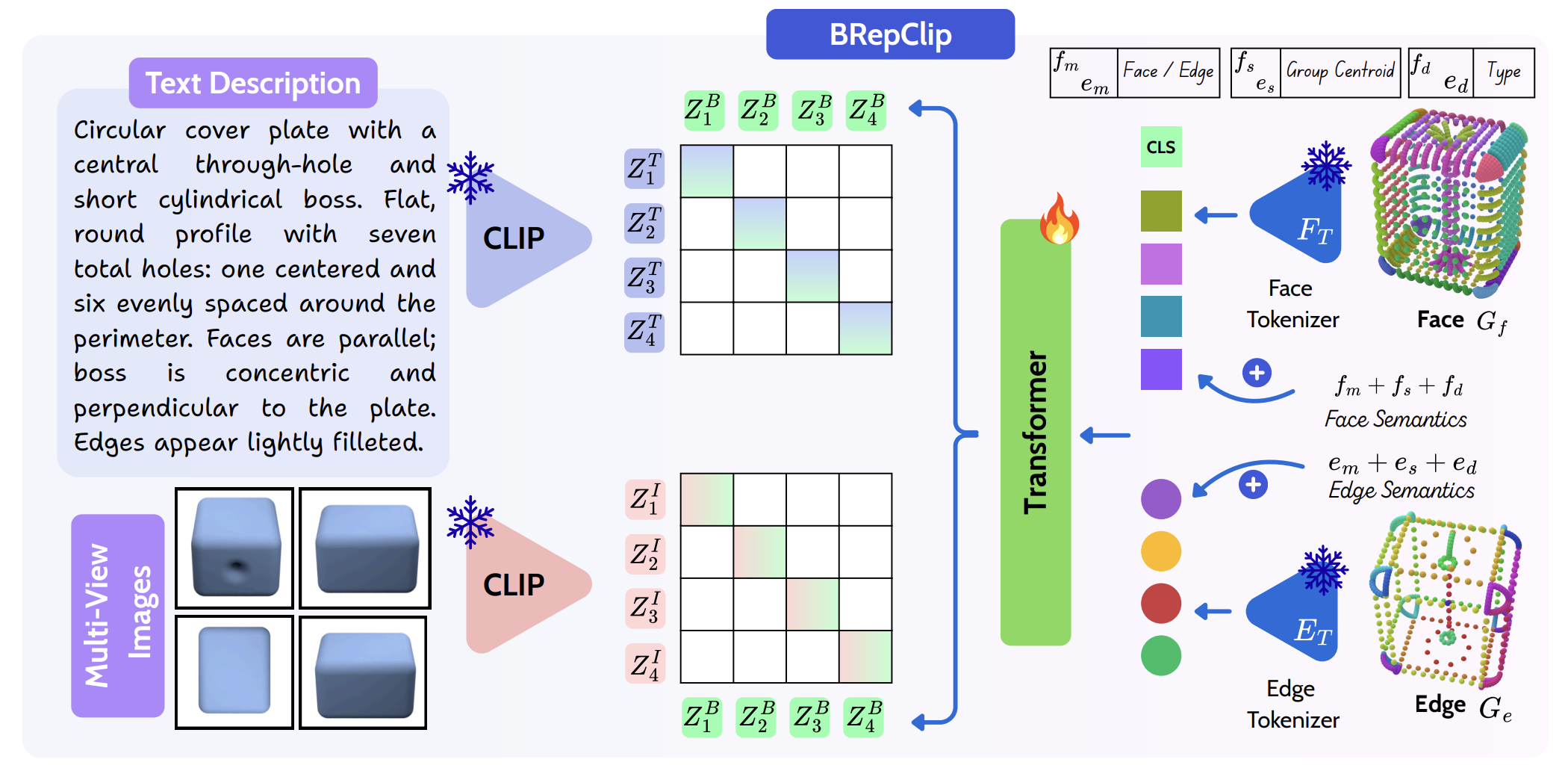
Stage 2
Contrastive BRep-text-image alignment
Applications
One embedding space, three CAD workflows.
BRepCLIP is trained as a representation model, but its embedding can be used directly in practical CAD workflows: retrieval, classification, and generation evaluation.
Experiment
Quantitative results
BRepCLIP is evaluated across text-to-CAD retrieval, zero-shot CAD classification, and CAD generation evaluation. Retrieval CD is scaled by 103.
Text-to-CAD Retrieval
Given a text query, models retrieve the matching CAD object from a full gallery using cosine similarity in the shared embedding space.
| Method | Top-1 | Top-5 | Top-10 | Top-20 | CD ↓ |
|---|---|---|---|---|---|
| Point-BERT [41] | 2.60 | 9.36 | 15.80 | 22.72 | 61.56 |
| PointNet [28] | 3.31 | 12.07 | 19.38 | 29.60 | 62.27 |
| PointMLP [25] | 0.90 | 3.50 | 6.00 | 9.50 | 68.43 |
| BRepEncoder | 4.30 | 16.30 | 24.70 | 33.90 | 61.11 |
| MixCon3D [7] | 1.20 | 2.10 | 4.20 | 8.12 | 74.18 |
| ULIP [39] | 2.30 | 4.00 | 7.40 | 12.20 | 63.48 |
| OpenShape [21] | 6.12 | 18.17 | 24.88 | 34.36 | 71.63 |
| BRepCLIP | 8.59 | 24.52 | 35.08 | 47.89 | 58.16 |
| Method | Top-1 | Top-5 | Top-10 | Top-20 | CD ↓ |
|---|---|---|---|---|---|
| Point-BERT [41] | 1.10 | 4.40 | 7.00 | 10.90 | 45.12 |
| PointNet [28] | 0.40 | 1.90 | 3.50 | 6.40 | 64.80 |
| PointMLP [25] | 1.10 | 3.70 | 6.70 | 9.30 | 54.55 |
| BRepEncoder | 2.10 | 8.20 | 13.20 | 19.00 | 40.32 |
| MixCon3D [7] | 0.19 | 1.74 | 2.33 | 5.12 | 69.83 |
| ULIP [39] | 0.70 | 2.90 | 4.60 | 7.10 | 67.33 |
| OpenShape [21] | 4.10 | 13.40 | 19.70 | 29.30 | 43.33 |
| BRepCLIP | 5.00 | 15.08 | 22.12 | 30.60 | 35.28 |
| Method | Top-1 | Top-5 | Top-10 | Top-20 | CD ↓ |
|---|---|---|---|---|---|
| Point-BERT [41] | 0.91 | 3.55 | 6.04 | 9.64 | 71.58 |
| PointNet [28] | 3.33 | 10.72 | 16.41 | 23.96 | 68.13 |
| PointMLP [25] | 1.02 | 3.79 | 6.39 | 10.20 | 75.51 |
| BRepEncoder | 4.82 | 14.30 | 21.06 | 29.55 | 68.48 |
| MixCon3D [7] | 0.18 | 2.33 | 3.88 | 6.54 | 94.15 |
| ULIP [39] | 0.92 | 3.11 | 5.06 | 7.95 | 91.41 |
| OpenShape [21] | 7.60 | 19.86 | 27.58 | 36.45 | 79.82 |
| BRepCLIP | 9.42 | 24.18 | 32.86 | 42.83 | 60.32 |
Zero-Shot Classification on FabWave
CAD embeddings are matched directly to class-level text descriptors without fine-tuning.
| Method | Top-1 | Top-5 | Top-10 |
|---|---|---|---|
| Point-BERT | 17.34 | 40.21 | 56.04 |
| PointNet | 15.74 | 38.78 | 54.37 |
| PointMLP | 18.80 | 41.00 | 59.02 |
| BRepEncoder | 21.81 | 43.40 | 60.74 |
| ULIP | 21.65 | 47.28 | 60.62 |
| MixCon3D | 34.10 | 63.93 | 78.18 |
| OpenShape | 33.58 | 68.73 | 81.73 |
| BRepCLIP | 38.62 | 70.28 | 86.71 |
Evaluation
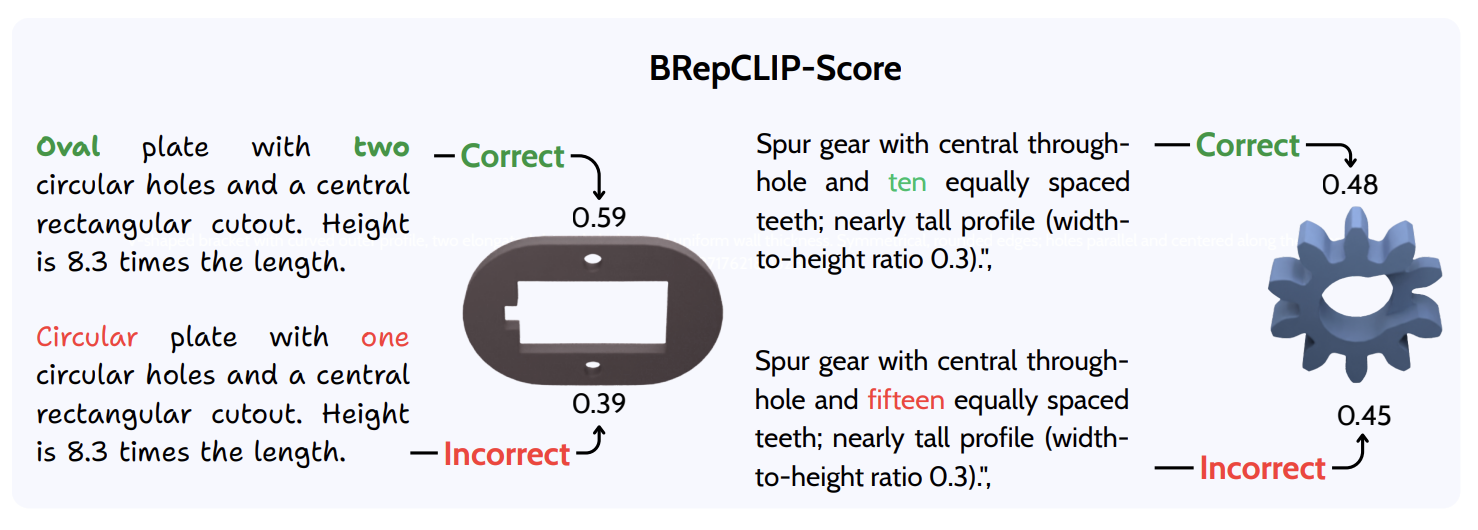
BRepCLIP-Score
BRepCLIP-Score evaluates whether generated CAD geometry matches a text prompt using the learned BRep embedding, making the metric sensitive to topology, hole counts, surface types, and edge structure.
Geometry distance
Chamfer Distance is computed between point samples from the generated CAD model and the target CAD geometry. Lower values indicate closer global shape reconstruction.
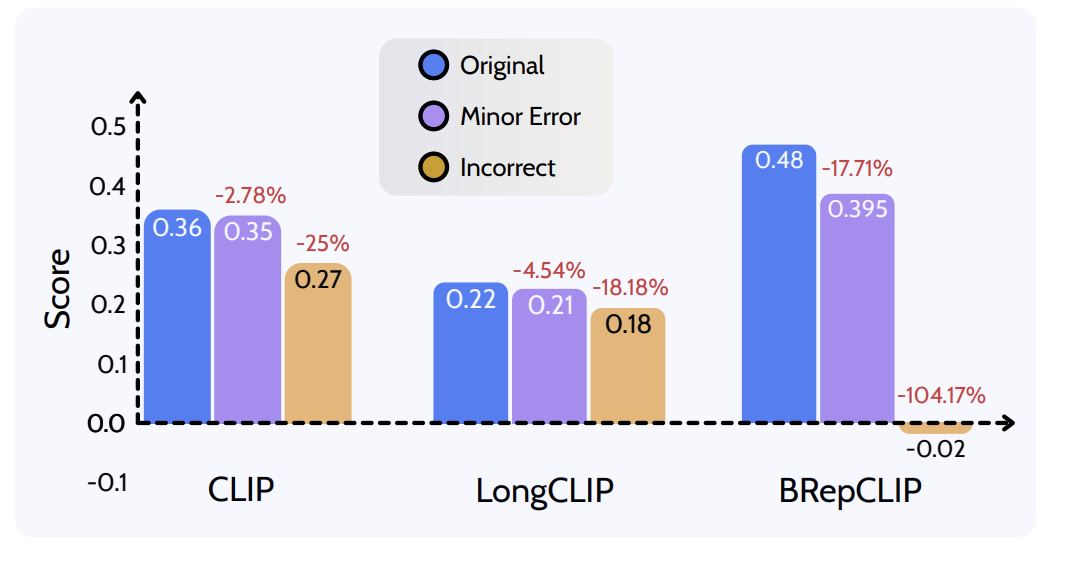
Image-text similarity
We render multiview images of each generated CAD model and compare them with the prompt using CLIP image and text embeddings. This captures visual alignment, but not native BRep structure.
Prompt-to-BRep similarity
The prompt embedding is compared directly with the generated CAD model's BRep embedding using cosine similarity, so errors in holes, surfaces, edges, and topology affect the score.
Semantic faithfulness
Five CAD designers and GPT-based evaluators score multiview renderings from 0 to 10 based on how faithfully each generated CAD model matches the input caption.
Text-to-CAD Generation Benchmark
BRepCLIP-Score is compared against CD, CLIP score, human ratings, and GPT ratings on generated CAD outputs from recent text-to-CAD methods.
| Method | CD ↓ | CLIP Score ↑ | Human Score ↑ | GPT Score ↑ | BRepCLIP Score ↑ |
|---|---|---|---|---|---|
| Ground Truth | - | 0.37 | 9.7 | 9.8 | 0.61 |
| DeepCAD | 86.54 | 0.24 | 2.2 | 2.4 | 0.15 |
| Text2CAD | 86.54 | 0.26 | 3.6 | 3.5 | 0.16 |
| CADRille | 155.80 | 0.26 | 3.5 | 3.7 | 0.16 |
| Text2CQ (Q3B) | 68.15 | 0.33 | 5.0 | 4.9 | 0.31 |
| Text2CQ (GL) | 71.27 | 0.32 | 4.6 | 4.5 | 0.25 |
| Text2CQ (CG) | 77.91 | 0.31 | 4.1 | 3.9 | 0.22 |
| CADFusion | 56.36 | 0.29 | 5.5 | 5.8 | 0.35 |
Collaborators
Contact and profiles
Author profile links follow the public project/profile pages used in related CAD generation work. Publicly available emails are listed where available.
Muhammad Usama
DFKI · RPTU Kaiserslautern-Landau · MindGarage
Didier Stricker
Scientific Director, DFKI Augmented Vision
Mohammad Sadil Khan*
Equal contributing supervisor · DFKI / RPTU
Muhammad Zeshan Afzal*
Equal contributing supervisor · DFKI / MindGarage